System Requirements
- Python version 3.10 or 3.11
- Mac (ARM or x64), Windows (x64), or Linux (x64)
What’s Vinyl?
Vinyl is Turntable’s framework for developing analytics infrastructure. The only thing you need to know is basic python. Vinyl is cross-dialect and integrates with your existing data stack. Vinyl can be accessed in places like BI tools, AI agents or data products and works the same if you have 10,000 rows of data or 100M. Vinyl constructs SQL queries under the hood to avoid pulling all of your data onto your machine and it supports data sources from cloud storage services like S3, databases like Postgres or data warehouses like BigQuery. Vinyl also supports reading from dbt projects. Learn more about our supported connectionsSetup your Environment
If you have an existing poetry project, run
poetry add "vinyl[dev]" and make
sure you’re in a poetry shell for the next step.For now, Vinyl projects must also be poetry projects. We’re working on adding support
for other package managers.
Create a Project
my_shop for this example.
Generate Sources
Sources are typed data schemas that help Vinyl understand what data is available. Sources can data warehouses (Snowflake, Bigquery), data lakes (Delta), cloud storage (S3, GCS) or even local files. See all of the supported connections here. Our demo project contains 3 sample csvs from the Ecuador grocery store dataset under thedata/ folder:
- stores.csv: A list of 54 grocery stores and their locations
- store_num_transactions.csv: The number of transactions at each store over time (2013-2017)
- holiday_events.csv: holiday dates in Ecuador (2013-2017)
my_shop/resources.py There’s a local resource created for you to work with our local demo files.
my_shop/resources.py
sources/local_filesystem/ that map to each csv file:
- stores.py
- holiday_events.py
- store_num_transactions.py
stores.py:
my_store/sources/local_filesystem/stores.py
@source annotation, we get a typed schema, column-level lineage support, powerful autocomplete and query validation across many different SQL dialects and resource types.
Now let’s do something with this source data.
Create a Model
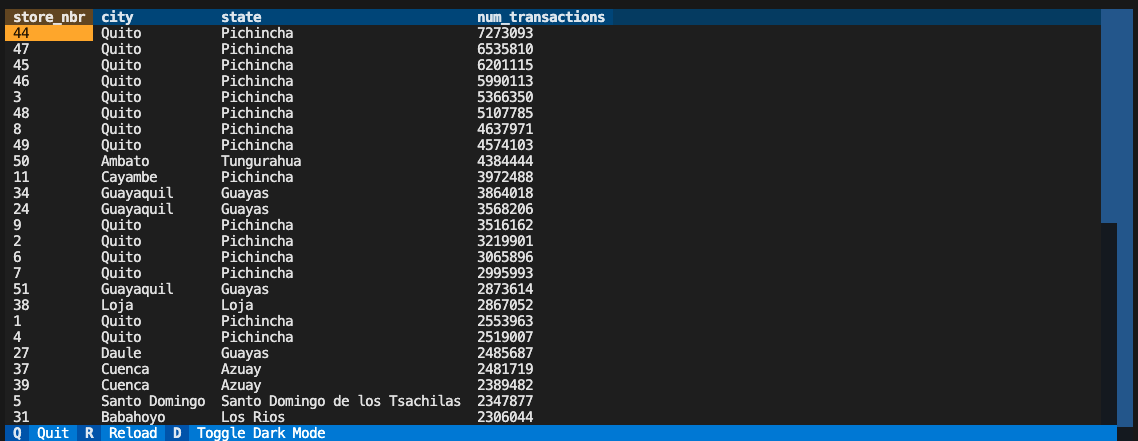
Models are semantic representations of your data. Models can be used in notebooks for analysis, embedded in BI tools or data products and referenced in other parts of your project. Vinyl provides a wide range of data transforms and complex SQL operations out of the box. We’ve created some models for you atmodels/models.py. Let’s take a look at top_stores:
models/models.py
@model annotation. In this example, we pass in the Stores source and StoreNumTransactions sources from earlier so we can aggregate the data to find the stores with the most transactions.
This kind of data work usually involves a lot of complex SQL. What makes Vinyl different here is our pipelined approach to data modeling, a simple API for performing transform operations, and cross-dialect SQL support. You can take the same model code above, change the source from a local file to Snowflake with the same schema and you’ll get the same result.
Now, let’s preview what this looks like using Vinyl’s built-in data preview tool.
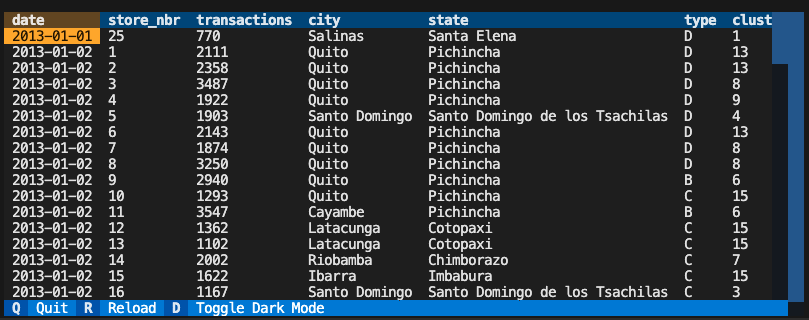
models/models.py
StoreNumTransactions and Stores. Let’s preview this data using:
Create a Metric
Metrics are a powerful feature in Vinyl that allows for tracking time series data. Metrics auto-generate complicated timeseries SQL for you and can be queried across dimensions and time buckets dynamically. Create a metric by passing in aMetricStore to your function and adding a @metric annotation. We’ll reference the same store_txns model from above.
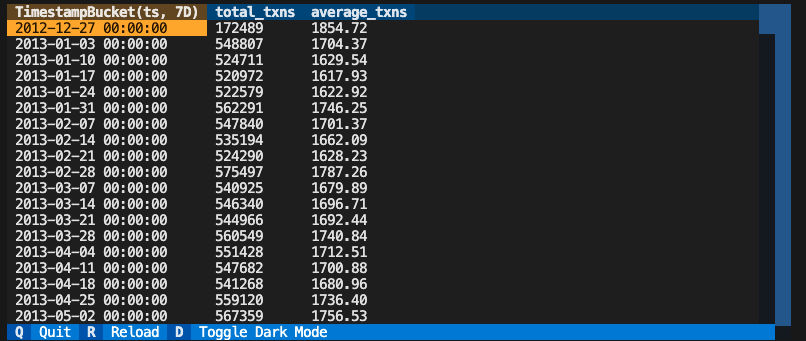
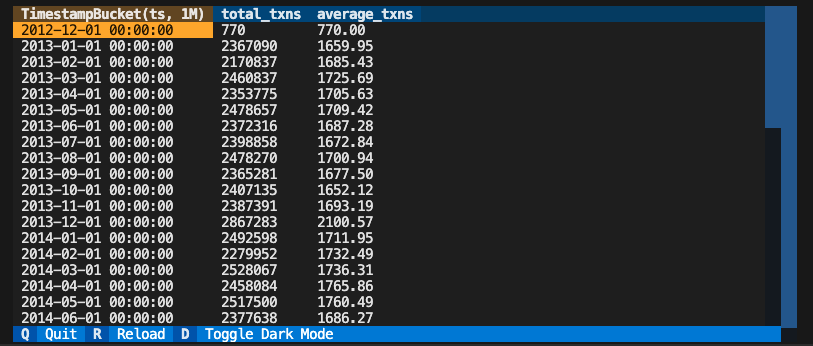
Deployment
While Vinyl is a great data modeling and analysis tool on it’s own, it’s also designed to be accessed in places like BI tools, AI agents or data products. You can orchestrate and deploy your Vinyl project using the CLI. By default, Vinyl runs workloads and serves data locally. For production use caes, learn more about our deployment options. Let’s get our project ready to be served by running thedeploy command:
serve command:
